Never in the history of human civilization has there been such unexpected phenomenon of generation of data in this world of digitization. Such mundane yet significant activities under the hood of social media interactions that ranges from financial transactions to public videos and reviews generates incessant volumes of data from varied sources. Such huge volumes of structured, semi-structured, and unstructured data have now transformed into Big Data-a term that portrays much voluminous data useful for analysis.
In this blog post we will describe the differences between these three types of Big Data with several examples. Make sure to checkout the previous post what is big data? :- https://navagyan.in/posts/what-is-big-data-challenges-and-solutions?draft_post=false&id=9f89db84-419e-4e8c-86e3-c788a0c69e39
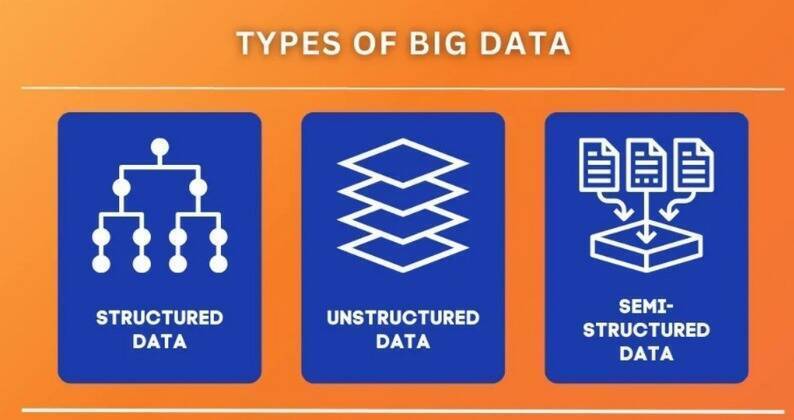
1. Structured Data
Probably the most common kind of data, though, is a structured data set. That is to say, the kinds of data are well organized and hence relatively easy to apply to analysis, often in rows and columns for easy comprehension. Easy to search and analyze by using standard tools, including databases, such as SQL. In other words, it's the kind of data that easily fits into a spreadsheet or relational database, such as:
Customer records ,Financial transactions,Inventory management systems.
Table format: by rows and columns
Advantages:Easy to handle and query: The information is already formatted a little easier to search, filter, or change in the tools of SQL
Neat: As the information already has a format; therefore, easy sorting or grouping
Disadvantages:Has low flexibility since it has structured data since it has inflexibility because data only takes information that can fit the pre-existing schema.
Not for complex data types: Multimedia files, emails and social interactions are very hard to categorize.
Example Situation: The sales database of a retail organization which stores every sale along with the product ID, date, number sold, and customer details is a great example of structured data.
2. Unstructured Data
On the other hand is unstructured data. It doesn’t have a fixed structure. This makes it difficult to arrange and analyze this type of data. Unstructured data is omnipresent, and it's growing day by day due to social media, videos, and other user-generated content.
Examples: Emails, text documents, videos, social media posts, and images.
Format: Unorganized-no fixed structure and can include multimedia formats.
Advantages: Crammed with depth: Although unstructured data cannot be structured, yet with tools such as NLP and ML, it owns an appreciable amount of depth.
Most fungible : *With unstructured data, it may represent quite any type of content - including blog posts or sensor data.
*Disadvantages:It is hard to analyze; special tools and techniques like data mining and ML are needed in order to unlock value from unstructured data.
Storage Requirements: Because they differ from one another, processing and handling unstructured data typically requires more cost.
*Illustration Scenario: *A company may explore what people have to say about it on Twitter mentions wherein the data is informal text, hashtags, and emojis are semi-structured data.
3. Semi-Structured Data
Therefore, semi-structured data is in the middle between structured and unstructured data. Although it is not tabular as in case of structured data, it orderly places its elements easily, like in semi-structured data; whereas, in case of unstructured data, the ordering of its elements is not so easy. Normally, a type of semi-structured data carries some tags or indicators in order to mark out its constituents; hence, the easier analysis.
Examples: A collection of files in XML, a collection of JSON documents, emails that carry structured fields like sender and receiver but whose body contains unstructured text as well
Formats: Semi-structured with headings or footers, though the general structure is not well defined
Benefits
Flexibility in organization: semi-structured data struck at finding a mid-point between being too loose and too organized.
More manageable: whereas the semi-structured data is relatively easier to process than unstructured data, several automated processing mechanisms can be used.
Disadvantages: Not freed from high-end tools yet,although the semi-structured data falls in the category of easier to deal with than unstructured data, the analysis still requires special tools.
For instance, API returns many JSON files which include some specific data points defined in those JSON files. Examples include data points associated with a user name, while the rest is associated with one product review that has not been well integrated into the relational database.
Conclusion
A data scientist and an IT professional need to understand the nature of Big Data entities, how such entities fall into three categories- Structured, Unstructured and Semi-Structured. These entities offer strengths and weaknesses in each category. Unlocking the full potential of Big Data is as much about appropriateness of tool as it is about the techniques that it uses. This would mean whether it's one on well-structured data from the database or insights derived from the social media chatter, knowing what differentiates them will help you make better decisions and dig valuable information out of the data that you gather.
Next post is gonna be about one of the tools for achieving this, stick around to find out







